 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeSyA: Neurosymbolic Automata
Dec 10, 2024Neurosymbolic Artificial Intelligence (NeSy) has emerged as a promising direction to integrate low level perception with high level reasoning. Unfortunately, little attention has been given to developing NeSy systems tailored to temporal/sequential problems. This entails reasoning symbolically over sequences of subsymbolic observations towards a target prediction. We show that using a probabilistic semantics symbolic automata, which combine the power of automata for temporal structure specification with that of propositional logic, can be used to reason efficiently and differentiably over subsymbolic sequences. The proposed system, which we call NeSyA (Neuro Symbolic Automata), is shown to either scale or perform better than existing NeSy approaches when applied to problems with a temporal component.
iASiS: Towards Heterogeneous Big Data Analysis for Personalized Medicine
Jul 09, 2024

The vision of IASIS project is to turn the wave of big biomedical data heading our way into actionable knowledge for decision makers. This is achieved by integrating data from disparate sources, including genomics, electronic health records and bibliography, and applying advanced analytics methods to discover useful patterns. The goal is to turn large amounts of available data into actionable information to authorities for planning public health activities and policies. The integration and analysis of these heterogeneous sources of information will enable the best decisions to be made, allowing for diagnosis and treatment to be personalised to each individual. The project offers a common representation schema for the heterogeneous data sources. The iASiS infrastructure is able to convert clinical notes into usable data, combine them with genomic data, related bibliography, image data and more, and create a global knowledge base. This facilitates the use of intelligent methods in order to discover useful patterns across different resources. Using semantic integration of data gives the opportunity to generate information that is rich, auditable and reliable. This information can be used to provide better care, reduce errors and create more confidence in sharing data, thus providing more insights and opportunities. Data resources for two different disease categories are explored within the iASiS use cases, dementia and lung cancer.
* 6 pages, 2 figures, accepted at 2019 IEEE 32nd International Symposium on Computer-Based Medical Systems (CBMS)
LSHTC: A Benchmark for Large-Scale Text Classification
Mar 30, 2015
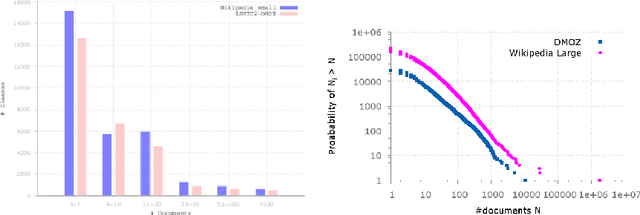
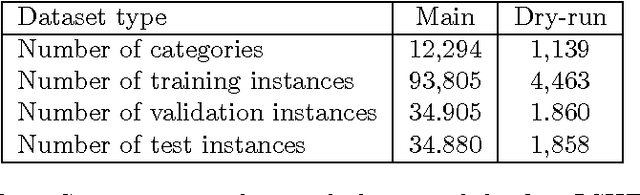
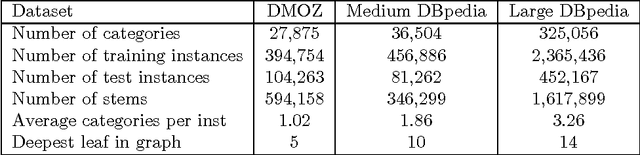
LSHTC is a series of challenges which aims to assess the performance of classification systems in large-scale classification in a a large number of classes (up to hundreds of thousands). This paper describes the dataset that have been released along the LSHTC series. The paper details the construction of the datsets and the design of the tracks as well as the evaluation measures that we implemented and a quick overview of the results. All of these datasets are available online and runs may still be submitted on the online server of the challenges.
Incremental Learning of Event Definitions with Inductive Logic Programming
Nov 22, 2014
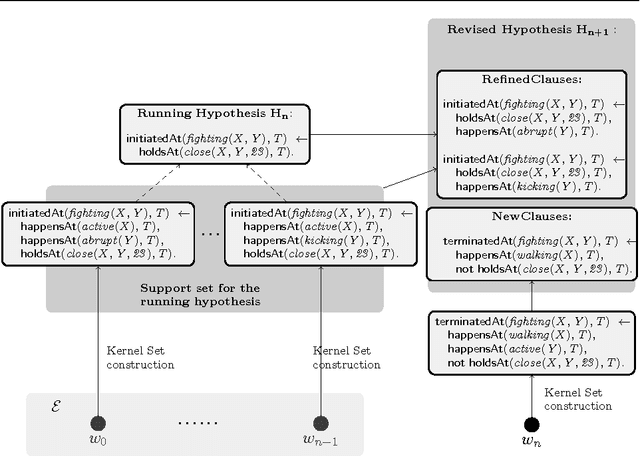
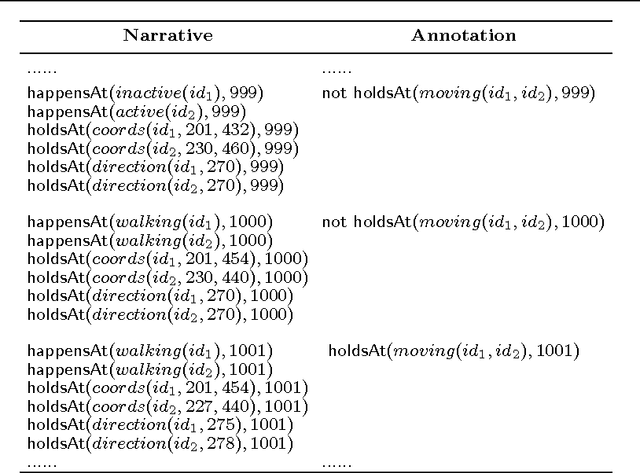
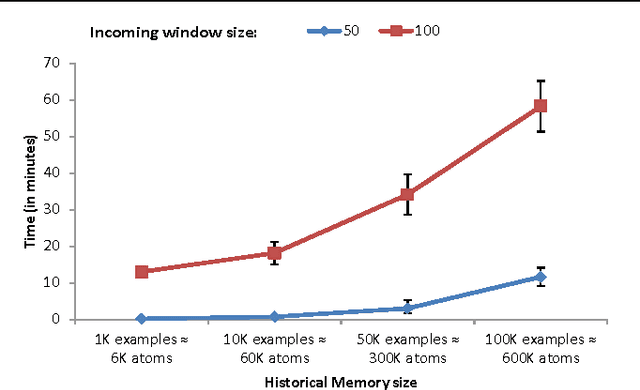
Event recognition systems rely on properly engineered knowledge bases of event definitions to infer occurrences of events in time. The manual development of such knowledge is a tedious and error-prone task, thus event-based applications may benefit from automated knowledge construction techniques, such as Inductive Logic Programming (ILP), which combines machine learning with the declarative and formal semantics of First-Order Logic. However, learning temporal logical formalisms, which are typically utilized by logic-based Event Recognition systems is a challenging task, which most ILP systems cannot fully undertake. In addition, event-based data is usually massive and collected at different times and under various circumstances. Ideally, systems that learn from temporal data should be able to operate in an incremental mode, that is, revise prior constructed knowledge in the face of new evidence. Most ILP systems are batch learners, in the sense that in order to account for new evidence they have no alternative but to forget past knowledge and learn from scratch. Given the increased inherent complexity of ILP and the volumes of real-life temporal data, this results to algorithms that scale poorly. In this work we present an incremental method for learning and revising event-based knowledge, in the form of Event Calculus programs. The proposed algorithm relies on abductive-inductive learning and comprises a scalable clause refinement methodology, based on a compressive summarization of clause coverage in a stream of examples. We present an empirical evaluation of our approach on real and synthetic data from activity recognition and city transport applications.
An evaluation of Naive Bayesian anti-spam filtering
Jun 07, 2000
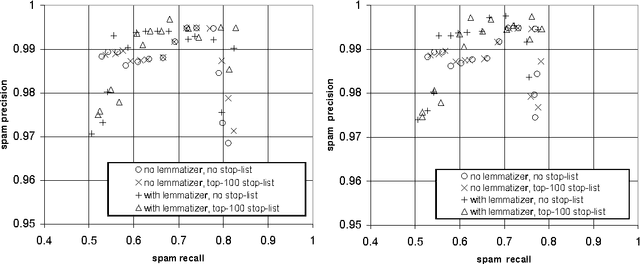
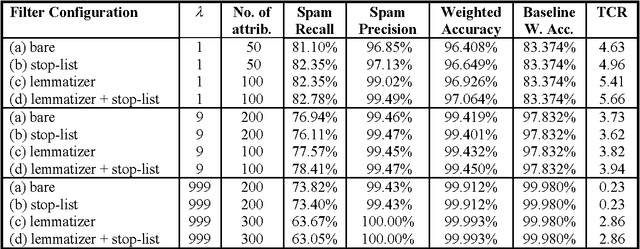
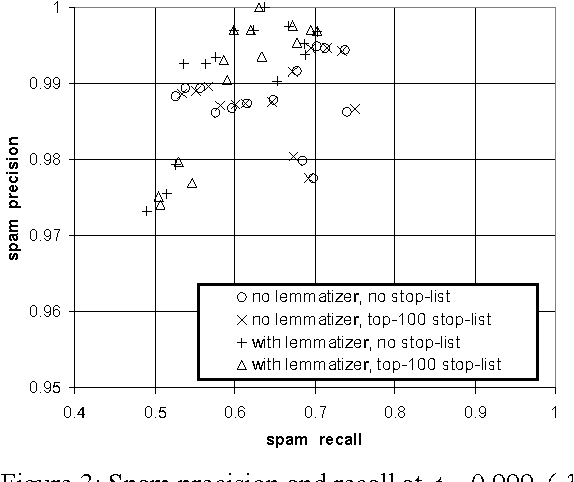
It has recently been argued that a Naive Bayesian classifier can be used to filter unsolicited bulk e-mail ("spam"). We conduct a thorough evaluation of this proposal on a corpus that we make publicly available, contributing towards standard benchmarks. At the same time we investigate the effect of attribute-set size, training-corpus size, lemmatization, and stop-lists on the filter's performance, issues that had not been previously explored. After introducing appropriate cost-sensitive evaluation measures, we reach the conclusion that additional safety nets are needed for the Naive Bayesian anti-spam filter to be viable in practice.
* 9 pages